Che cos'è lo scraping web? Come raccogliere dati da siti Web
Annuncio pubblicitario
I Web scraper raccolgono automaticamente informazioni e dati che sono normalmente accessibili solo visitando un sito Web in un browser. In questo modo autonomamente, gli script di web scraping aprono un mondo di possibilità nel data mining, nell'analisi dei dati, nell'analisi statistica e molto altro.
Perché il Web Scraping è utile
Viviamo in un'epoca in cui le informazioni sono più prontamente disponibili rispetto a qualsiasi altro momento. L'infrastruttura utilizzata per fornire queste stesse parole che stai leggendo è un canale per più conoscenza, opinione e notizie di quanto sia mai stato accessibile alle persone nella storia delle persone.
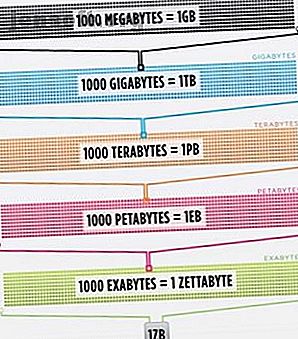
Tanto che, in effetti, il cervello della persona più intelligente, migliorato al 100% di efficienza (qualcuno dovrebbe fare un film su questo), non sarebbe ancora in grado di contenere 1/1000 dei dati memorizzati su Internet solo negli Stati Uniti .
Cisco ha stimato nel 2016 che il traffico su Internet ha superato uno zettabyte, ovvero 1.000.000.000.000.000.000.000.000 di byte, o un sestilione di byte (vai avanti, ridacchiando a sestillion). Uno zettabyte è di circa quattromila anni di streaming su Netflix. Ciò equivarrebbe a se tu, intrepido lettore, dovessi trasmettere in streaming Office dall'inizio alla fine senza interrompere 500.000 volte.

Tutti questi dati e informazioni sono molto intimidatori. Non tutto è giusto. Non molto è rilevante per la vita di tutti i giorni, ma sempre più dispositivi forniscono queste informazioni dai server di tutto il mondo ai nostri occhi e nei nostri cervelli.
Poiché i nostri occhi e il nostro cervello non riescono davvero a gestire tutte queste informazioni, il web scraping è emerso come un metodo utile per la raccolta di dati a livello di codice da Internet. Web scraping è il termine astratto per definire l'atto di estrazione dei dati dai siti Web al fine di salvarli localmente.
Pensa a un tipo di dati e probabilmente puoi raccoglierlo raschiando il web. Elenchi immobiliari, dati sportivi, indirizzi e-mail delle imprese nella tua zona e persino i testi del tuo artista preferito possono essere cercati e salvati scrivendo una piccola sceneggiatura.
In che modo un browser ottiene i dati Web?
Per comprendere i raschiatori web, dovremo capire come funziona prima il web. Per accedere a questo sito Web, hai digitato "makeuseof.com" nel tuo browser Web o hai fatto clic su un collegamento da un'altra pagina Web (dicci dove, sul serio, vogliamo sapere). Ad ogni modo, i prossimi due passi sono gli stessi.
Innanzitutto, il tuo browser prenderà l'URL che hai inserito o cliccato (Suggerimento: passa con il mouse sul link per vedere l'URL nella parte inferiore del browser prima di fare clic per evitare di essere punk) e formerà una "richiesta" da inviare a un server. Il server elaborerà quindi la richiesta e invierà una risposta.
La risposta del server contiene HTML, JavaScript, CSS, JSON e altri dati necessari per consentire al browser Web di formare una pagina Web per il piacere della visualizzazione.
Ispezione di elementi Web
I browser moderni ci consentono alcuni dettagli su questo processo. In Google Chrome su Windows puoi premere Ctrl + Maiusc + I o fare clic con il pulsante destro del mouse e selezionare Controlla . La finestra presenterà quindi una schermata simile alla seguente.

Un elenco di opzioni a schede allinea la parte superiore della finestra. Di interesse in questo momento è la scheda Rete . Ciò fornirà dettagli sul traffico HTTP come mostrato di seguito.

Nell'angolo in basso a destra vediamo le informazioni sulla richiesta HTTP. L'URL è quello che ci aspettiamo e il "metodo" è una richiesta HTTP "GET". Il codice di stato dalla risposta è elencato come 200, il che significa che il server ha considerato la richiesta valida.
Sotto il codice di stato si trova l'indirizzo remoto, che è l'indirizzo IP pubblico del server makeuseof.com. Il client ottiene questo indirizzo tramite il protocollo DNS Perché la modifica delle impostazioni DNS aumenta la velocità di Internet Perché la modifica delle impostazioni DNS aumenta la velocità di Internet La modifica delle impostazioni DNS è una di quelle piccole modifiche che possono avere grandi ritorni sulla velocità di Internet quotidiana. Leggi di più .
La sezione successiva elenca i dettagli sulla risposta. L'intestazione della risposta non contiene solo il codice di stato, ma anche il tipo di dati o contenuto che contiene la risposta. In questo caso, stiamo esaminando "text / html" con una codifica standard. Questo ci dice che la risposta è letteralmente il codice HTML per rendere il sito web.

Altri tipi di risposte
Inoltre, i server possono restituire oggetti dati come risposta a una richiesta GET, anziché solo HTML per il rendering della pagina Web. Un'interfaccia di programmazione (o API) di un sito Web Cosa sono le API e come sono le API aperte che cambiano Internet Cosa sono le API e come sono le API aperte che cambiano Internet Ti sei mai chiesto come i programmi sul tuo computer e i siti web che visiti "parlano" l'un l'altro? Leggi di più in genere utilizza questo tipo di scambio.
Esaminando la scheda Rete come mostrato sopra, puoi vedere se esiste questo tipo di scambio. Quando si esamina la classifica aperta di CrossFit, viene visualizzata la richiesta di riempire la tabella con i dati.

Facendo clic sulla risposta, vengono visualizzati i dati JSON anziché il codice HTML per il rendering del sito Web. I dati in JSON sono una serie di etichette e valori, in un elenco stratificato e delineato.

L'analisi manuale del codice HTML o l'analisi di migliaia di coppie chiave / valore di JSON è molto simile alla lettura di Matrix. A prima vista, sembra incomprensibile. Potrebbero esserci troppe informazioni per decodificarle manualmente.
Web Scrapers to the Rescue!
Ora, prima di andare a chiedere la pillola blu per uscire da qui, dovresti sapere che non dobbiamo decodificare manualmente il codice HTML! L'ignoranza non è felicità e questa bistecca è deliziosa.
Un web scraper può svolgere queste difficili attività per te L'API Scrapestack semplifica la raschiatura di siti Web per i dati L'API Scrapestack semplifica la raschiatura di siti Web per i dati Cerchi un raschietto web potente ed economico? L'API scrapestack è gratuita per l'avvio e offre molti strumenti utili. Leggi di più . I framework di scraping sono disponibili in Python, JavaScript, Node e altre lingue. Uno dei modi più semplici per iniziare a raschiare è usando Python e Beautiful Soup.
Scraping un sito Web con Python
Per iniziare bastano poche righe di codice, purché tu abbia installato Python e BeautifulSoup. Ecco un piccolo script per ottenere la fonte di un sito Web e lasciare che BeautifulSoup lo valuti.
from bs4 import BeautifulSoup import requests url = "http://www.athleticvolume.com/programming/" content = requests.get(url) soup = BeautifulSoup(content.text) print(soup) Molto semplicemente, stiamo facendo una richiesta GET a un URL e quindi inserendo la risposta in un oggetto. La stampa dell'oggetto visualizza il codice sorgente HTML dell'URL. Il processo è come se andassimo manualmente sul sito Web e facessimo clic su Visualizza sorgente .
In particolare, questo è un sito Web che pubblica allenamenti in stile CrossFit ogni giorno, ma solo uno al giorno. Possiamo costruire il nostro raschietto per ottenere l'allenamento ogni giorno e quindi aggiungerlo a un elenco aggregato di allenamenti. In sostanza, possiamo creare un database storico basato su testo di allenamenti che possiamo facilmente cercare.
La magia di BeaufiulSoup è la capacità di cercare in tutto il codice HTML usando la funzione findAll () integrata. In questo caso specifico, il sito Web utilizza diversi tag "sqs-block-content". Pertanto, lo script deve scorrere tutti questi tag e trovare quello che ci interessa.
Inoltre, ci sono un certo numero di
tag nella sezione. Lo script può aggiungere tutto il testo di ciascuno di questi tag a una variabile locale. Per fare ciò, aggiungi un semplice ciclo allo script:
for div_class in soup.findAll('div', {'class': 'sqs-block-content'}): recordThis = False for p in div_class.findAll('p'): if 'PROGRAM' in p.text.upper(): recordThis = True if recordThis: program += p.text program += '\n' Ecco! È nato un raschietto web.
Scaling Up Scraping
Esistono due percorsi per andare avanti.
Un modo per esplorare il web scraping è utilizzare gli strumenti già creati. Web Scraper (grande nome!) Ha 200.000 utenti ed è semplice da usare. Inoltre, Parse Hub consente agli utenti di esportare i dati acquisiti in Excel e Fogli Google.
Inoltre, Web Scraper fornisce un plug-in di Chrome che consente di visualizzare la modalità di creazione di un sito Web. La cosa migliore, a giudicare dal nome, è OctoParse, un potente raschietto con un'interfaccia intuitiva.
Infine, ora che conosci lo sfondo del web scraping, solleva il tuo piccolo raschietto web per poter eseguire la scansione e l'esecuzione Come costruire un crawler Web di base per estrarre informazioni da un sito Web Come costruire un crawler Web di base per estrarre informazioni da un Sito Web Hai mai desiderato acquisire informazioni da un sito Web? Puoi scrivere un crawler per navigare nel sito Web ed estrarre esattamente ciò di cui hai bisogno. Leggere di più da solo è uno sforzo divertente.
Scopri di più su: Python, Web Scraping.

